Access information in scanned PDF documents and add it to the AI chat context
The OCR extension reads text content from images. For example, the content of scanned PDF documents can thus be included in the search. You can copy text content directly from images and paste it into the document you are working on or add the text to the context of the AI chat.
This is how it works
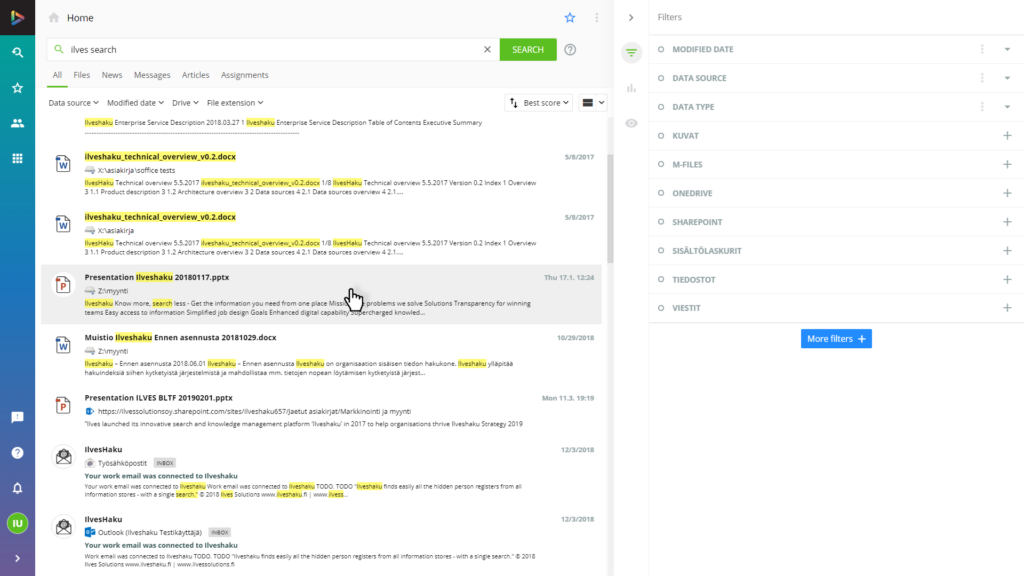
Choose a search result
Search and select any file from the search results.
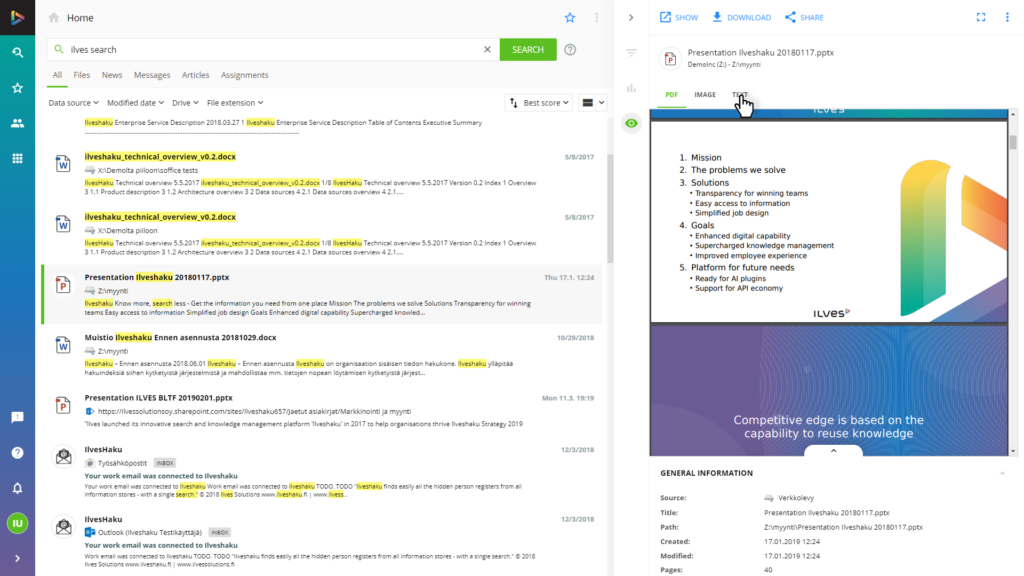
Choose text
Select TEXT in the preview. OCR automatically reads the text from the chosen image and takes it to the preview to be easily copied.
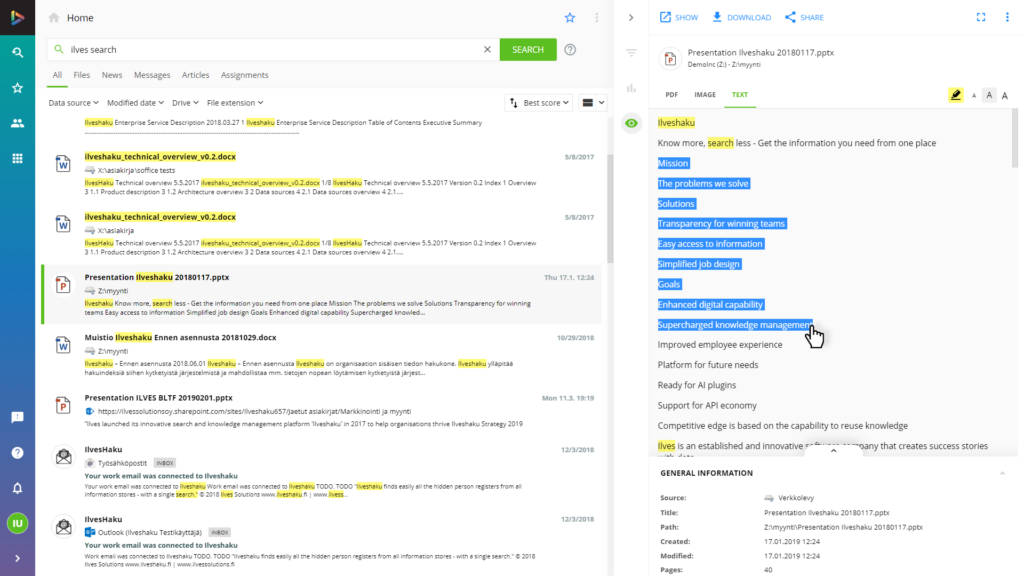
Browse and copy content
Browse and copy content: Browse, copy and reuse text by pasting it into the document you are working on. Easily add the text to the AI chat context by clicking ADD TO CHAT.
FAQ
Frequently Asked Questions
What technology Ilves Search uses for text recognition (OCR)?
By default Ilves Search uses Tesserract 4 neutral Network engine. Other OCR services can also be used.
Does Ilves Search modify documents during the OCR process?
No. Ilves Search does not modify original documents. Recognized text is stored to the Ilves Search database.
Which file types are supported?
Ilves Search can recognize text from almost all image types and Pdf documents.
I have a lot of old scanned documents in pdf format Which do not have OCR info. Can I Find the contacts based on scanned documents content?
Yes. Once Ilves Search has analysed the Document the Document can be found by the recognized words.
Can I copy the recognised text to the clipboard?
Yes. Just preview the Document through Ilves Search User interface and copy text through Pdf or Text tab. You need to have Advanced Preview extension enabled.
